 2023-10-07
2023-10-07
 分享至:
分享至:
近日,计算机学院信息检索研究室关于自然语言处理的多项研究成果被国际顶级会议和期刊录用,包括被第六十一届国际计算语言学会议ACL2023录用3篇,被第三十二届国际联合人工智能会议IJCAI2023录用1篇,被国际多媒体顶会ACM MM2023录用1篇,被国际知识和数据工程领域顶级期刊IEEE Transactions on Knowledge and Data Engineering(TKDE)录用1篇,以上会议和期刊均为中国计算机学会(CCF)推荐的A类会议和期刊。
信息检索研究室主要从事人工智能与自然语言处理的研究与应用,近期研究聚焦于信息推荐、信息抽取和情感计算等,获得了国家重点研发计划和国家自然科学基金的支持。
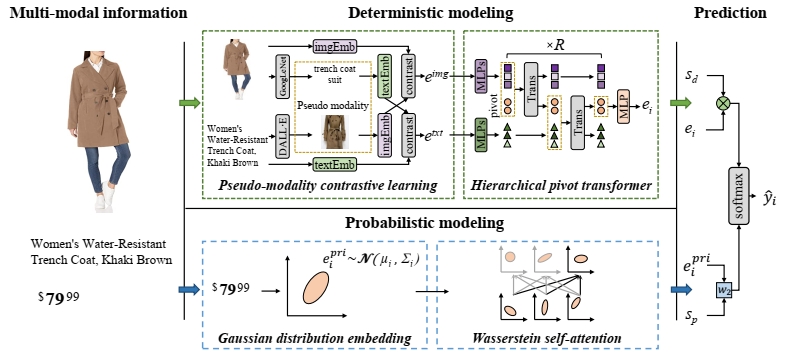
论文1:博士生张晓堃、徐博、杨亮、林鸿飞老师等共同完成的研究成果被数据挖掘顶级期刊IEEE Transaction on Knowledge and Data Engineering(TKDE)录用,该期刊为中国科学院一区。论文题目为“Beyond Co-occurrence: Multi-modal Session-based Recommendation”。
会话推荐旨在根据匿名用户短期行为序列预测用户偏好,进而为其提供个性化推荐服务。现有的会话推荐方法侧重于挖掘会话中由商品ID暴露的商品共现模式,而忽略了真正吸引用户与特定商品产生交互行为的是页面上展示的关于商品的多模态信息。这些多模态信息可以分为描述型信息(商品的图片和文本),数值型信息(商品的价格)。因此,论文提出了一个多模态会话推荐模型(MMSBR)对这些多模态信息进行统一建模,以便更好地理解用户意图,提升会话推荐的性能。具体而言,论文设计了一种伪模态对比学习来提升对商品图片和文本的表示学习;并提出了一种层次枢轴transformer来融合异构的图片和文本信息,进而表示商品的描述性特征。同时,采用高斯分布表示数值信息,设计了Wasserstein自注意力来处理价格对用户的概率影响模式。大量实验证明了所提出的MMSBR的有效性。进一步的分析也证明了MMSBR可以有效地缓解会话推荐中的冷启动问题。
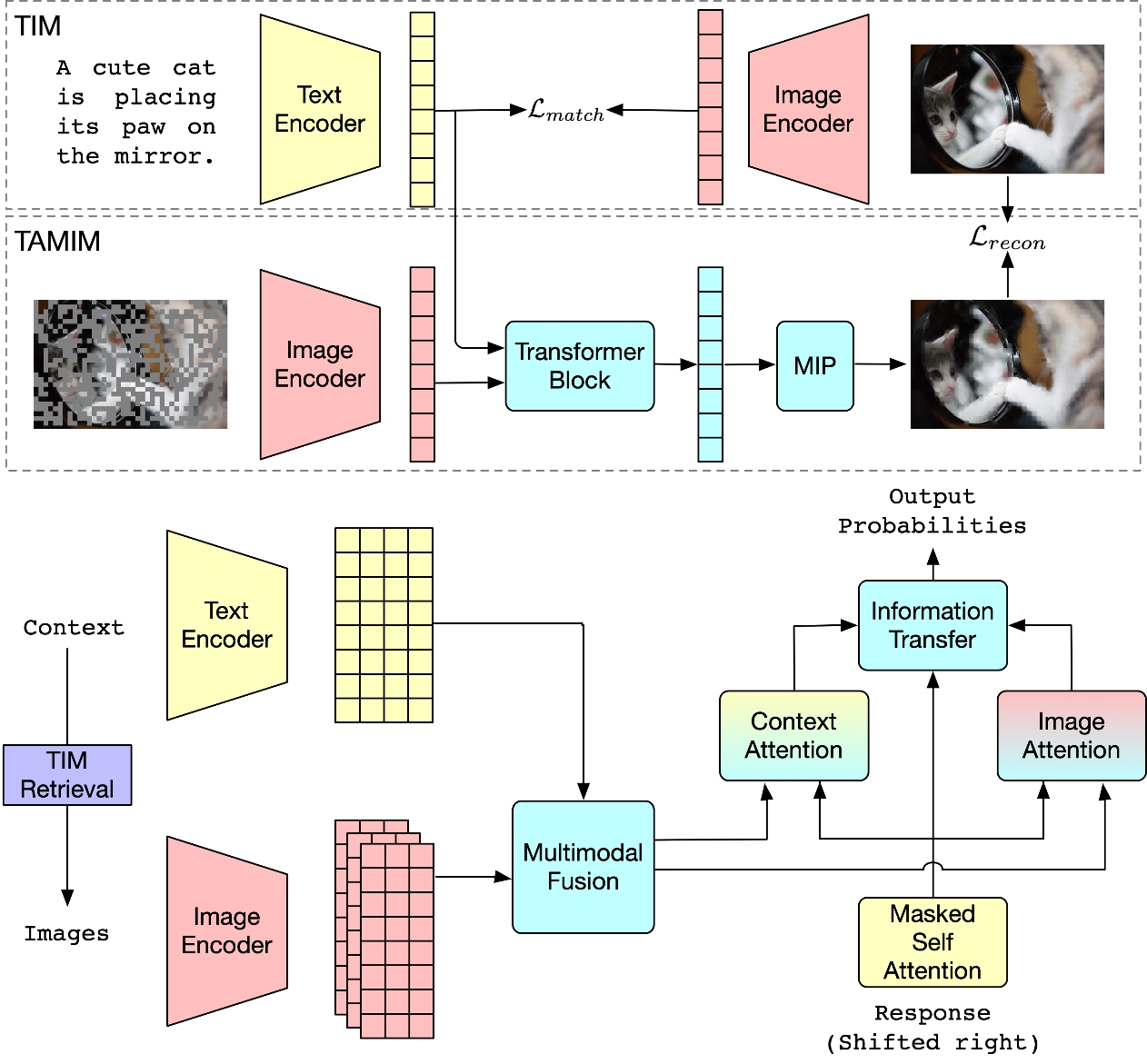
论文2:博士生张博、王健、徐博、杨亮和林鸿飞老师等共同完成的研究成果被国际多媒体处理顶级会议ACM MM2023录用为长文。论文题目为“ZRIGF: An Innovative Multimodal Framework for Zero-Resource Image-Grounded Dialogue Generation”。
图像引导的对话系统通过整合视觉信息,能产生高质量的回复生成。然而,现有模型在零资源情况下往往难以有效地利用这些信息,主要是因为图像和文本模态之间存在差异。为了克服这一挑战,提出了一个创新的多模态框架(ZRIGF),它可以在零资源情况下整合图像引导信息进行对话生成。ZRIGF实施了两阶段的学习策略,包括对比式预训练和生成式预训练。对比式预训练包括一个文本-图像匹配模块,该模块将图像和文本映射到一个统一的编码向量空间中,以及一个文本辅助的遮蔽图像建模模块,该模块保留预训练的视觉特征并进一步促进多模态特征对齐。生成式预训练采用多模态融合模块和信息传递模块,基于多模态表示生成有洞见的回复。在基于文本和图像引导的对话数据集上进行的全面实验证明了ZRIGF在生成与上下文相关和信息丰富的回复方面的有效性。同时,在图像引导的对话数据集中采用了完全零资源的情景,以展示所提出的框架在新领域的强大泛化能力。
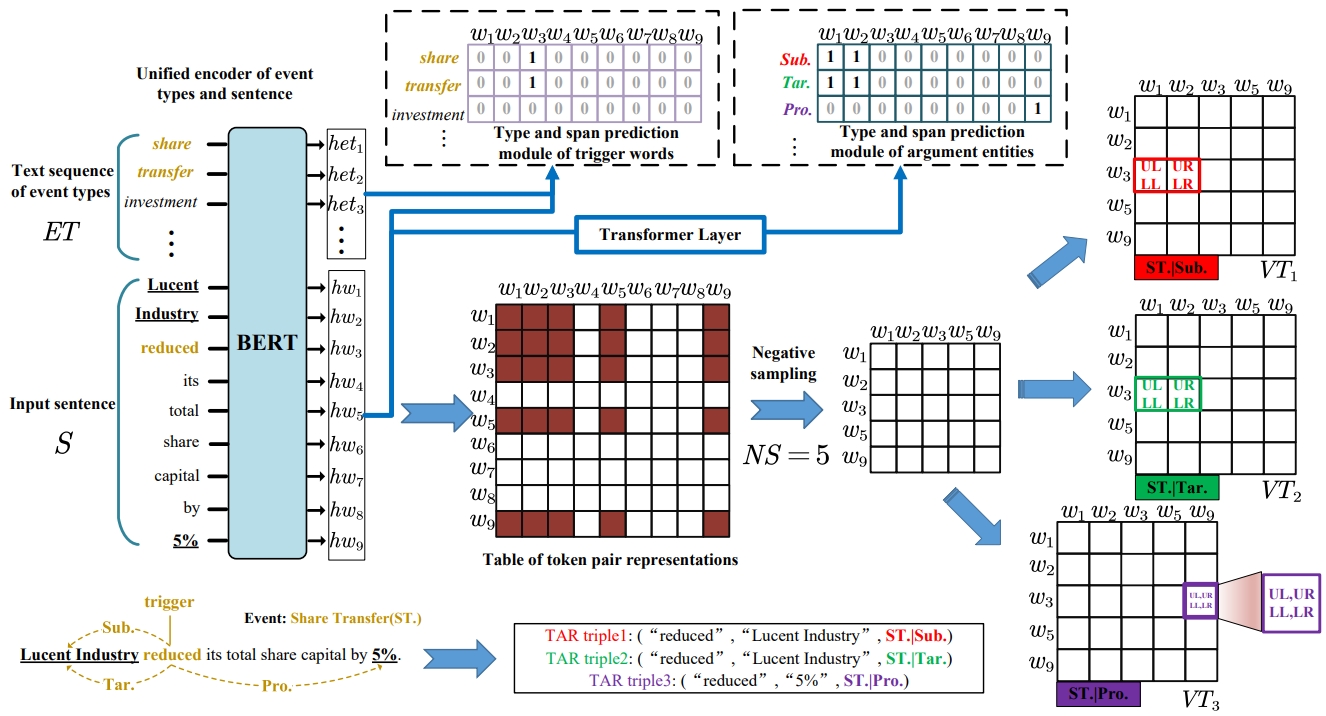
论文3:博士生宁金忠、杨志豪、孙媛媛和林鸿飞老师共同完成的研究成果被国际联合人工智能会议IJCAI2023录用为长文。论文题目为“ODEE: A One-Stage Object Detection Framework for Overlapping and Nested Event Extraction”。
近年来,嵌套与重叠事件抽取受到了广泛关注。已有的研究主要关注于平事件的抽取,忽略了文本中广泛存在的嵌套与重叠事件。论文引入了目标检测框架来解决填表事件抽取任务,提出的一阶段事件抽取器叫做ODEE,可以解决嵌套与重叠事件抽取问题。论文所提的模型中包含基于目标区域顶点的标注方案和两个预测事件触发词和要元实体类型和边界范围的辅助任务,充分利用了事件元素的跨度信息。除此之外,在训练阶段,引入了表格单元的负采样方法来解决表格单元的正负样本不均衡的问题。该负采样策略在提升模型性能的同时提高了模型的计算效率。实验结果表明,ODEE在三个基准嵌套与重叠事件抽取数据集上取得了最佳性能(i.e., FewFC, Genia11, and Genia13)。与此同时,ODEE相比已有方法,取得了最快推理速度和最少参数量等,证明ODEE模型具有很高的计算效率。
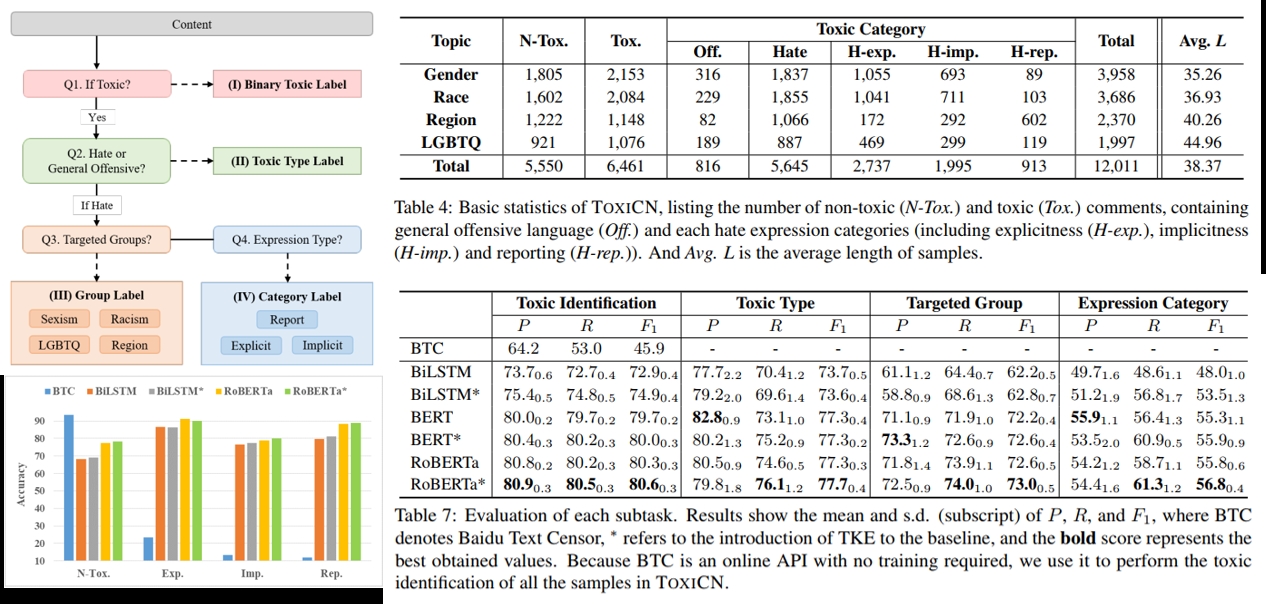
论文4:硕士生卢俊宇、徐博、杨亮和林鸿飞老师等共同完成的研究成果被自然语言处理顶会ACL2023录用为长文。论文题目是“Facilitating Fine-grained Detection of Chinese Toxic Language: Hierarchical Taxonomy, Resources, and Benchmarks”。
在社交媒体平台上,有毒言论的肆虐对社会造成了严重的危害。相较于英文,中文有毒言论检测的相关研究明显滞后。现有的数据集缺乏对有毒言论的毒性类型和表达方式进行细粒度注释,忽略了具有隐式毒性的样本。因此有必要促进了中文有毒言论的细粒度检测。首先,构建了Monitor Toxic Frame,这是一个层次的分类学框架,用于分析有毒类型和表达方式。然后,提出了一个细粒度的中文有毒言论数据集ToxiCN,包括显式毒性和隐式毒性样本。还构建了包含隐性亵渎的侮辱性词典,并提出了Toxic Knowledge Enhancement (TKE)结合词汇特征来检测有毒言论。在实验阶段,验证了TKE的有效性,并对研究结果进行了系统的定量和定性分析。
论文5:博士生闵昶榮、徐博、杨亮和林鸿飞老师等共同完成的研究成果被自然语言处理顶会ACL2023录用为长文。论文题目为“Just Like a Human Would, Direct Access to Sarcasm Augmented with Potential Result and Reaction”。
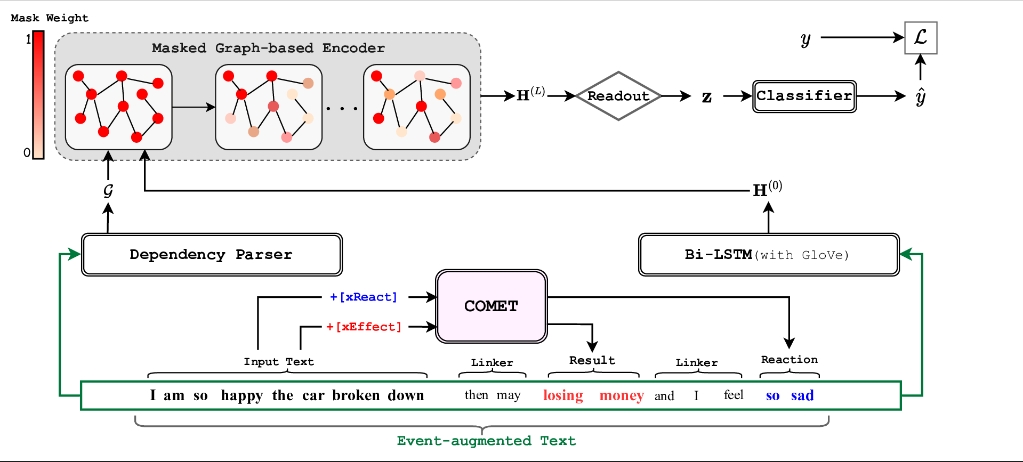
受人类对于讽刺的认知过程的启发,提出了一种潜在结果与心理反应增强的讽刺检测方法。基于认知语言学中The Direct Access理论,将每个讽刺样本视为一个不完整的版本,缺少与隐式负面情景相关的信息,这些信息包括讽刺样本可能引起的可能结果以及听众的心理反应。为此,利用预训练外部常识推理工具COMET,在[xEffect]和[xReact]关系的引导下,进一步推断每个反讽样本的可能结果以及心理反应。并在原始反讽样本的基础上,进一步构建增强样本。最后,利用降噪图编码器进一步学习增强样本的语义表示并得到样本预测结果。在四个不同规模的公开反讽识别数据集上进行实验,结果表明SD-APRR相比于最新基线模型有明显提升。此项研究工作同时说明在深度学习时代,传统语言学、心理学相关理论仍具有重要作用。
论文6:博士生宁金忠、杨志豪、孙媛媛和林鸿飞老师共同完成的研究成果被自然语言处理顶会ACL2023录用为长文。论文题目为“OD-RTE: A One-Stage Object Detection Framework for Relational Triple Extraction”。
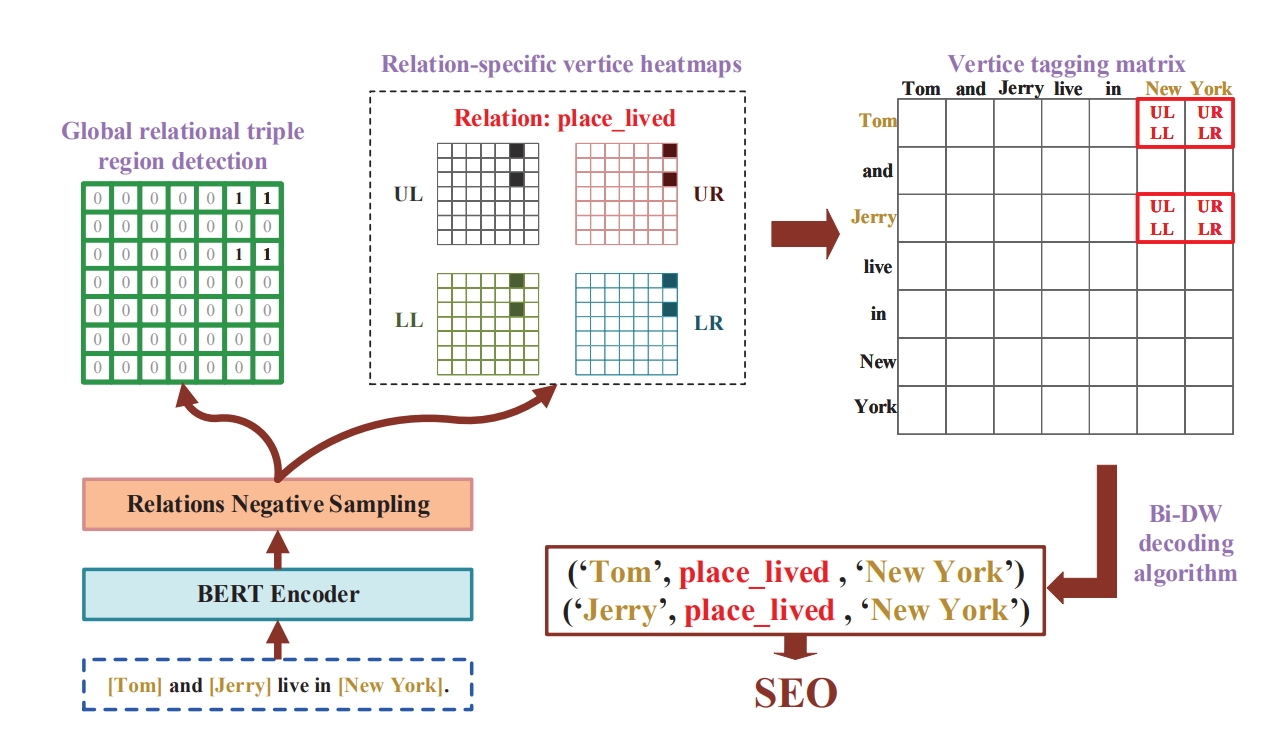
关系三元组抽取(RTE)任务是一项基础且重要的信息抽取任务。最近,基于填表的RTE方法受到了很多关注。尽管基于填表的信息抽取方法取得了成功,但仍存在一些固有问题,例如未充分利用三元组的区域信息。在这项工作中,将基于填表方法的RTE任务视为目标检测任务,并提出了一种基于单阶段目标检测框架的关系三元组抽取方法(OD-RTE)。在这个框架中,基于顶点的边界框检测,结合辅助的全局关系三元组区域检测,确保了三元组的区域信息能够得到充分利用。同时,所提出的解码方案可以提取所有嵌套与重叠类型的三元组。此外,在训练阶段的关系负采样策略显著提高了训练效率,同时缓解了正负关系的不平衡。实验结果表明:1)OD-RTE在两个广泛使用的基准数据集(NYT和WebNLG)上实现了最先进的性能。2)与最先进的的表格填充方法相比,OD-RTE实现了更快的训练和推理速度,并降低了GPU内存占用量。
来源:电子信息与电气工程学部
编辑:王一婷
审核:常思萌
 最新动态
最新动态
 投稿入口
投稿入口
 使用说明
使用说明